
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- ssh
- ES6
- post
- sessionStorage
- AWS RDS
- Java
- 인생이재밌다
- spread operator
- node.js
- javascript
- terminationGracePeriodSeconds
- git
- json
- html
- AWS
- 영화예매
- zombie-hit apartment
- mongodb
- ajax
- AWS Route53
- Bootstrap
- Get
- Kubernetes
- MySQL Error
- jsp
- mysql
- chartjs
- spring
- 예매로직
- topologySpreadConstraints
- Today
- Total
jongviet
May 19, 2021 - MySQL 총정리 - 2 본문
*5월19일
-어제에 이어 join, view, limit, index, case, group by & having 등을 정리해보자.
1)group by, having, case, order by
-group by 칼럼의 데이터를 그룹화시켜서 집계 데이터 형식으로 만드는 것
-group by로 묶을 시, 집계함수 생각해야함(aggregation);
-의류 브랜드 별 매출 금액, 카드 별 현금 별 매출 금액 등
select deptno, sum(sal) from emp group by deptno;
select deptno, count(sal), sum(sal), format(avg(sal), 2), max(sal), stddev(sal), variance(sal) from emp group by deptno;
*having 절
-- from에서 읽어온 테이블의 조건을 부여할 때는 where
-- group by에서 읽어온 데이터의 조건을 부여할 때는 having
-- where이 group by 보다 먼저 실행듸므로 별도의 조건절이 필요.
-- from -> where -> group by -> having -> order by -> select
select job, count(empno) from emp where sal > 1000 group by job having count(empno) > 2 order by count(empno) desc;
*case syntax = if else문;
select ename, sal,
case
when sal < 1000 then '1 Group'
when sal < 2000 then '2 Group'
when sal < 3000 then '3 Group'
else 'Top Group'
end as sal_group
from emp order by sal_group asc;
-- order by 칼럼 번호 순서대로 가능함 / 3번째 칼럼
select ename, sal,
case
when sal < 1000 then '1 Group'
when sal < 2000 then '2 Group'
when sal < 3000 then '3 Group'
else 'Top Group'
end as sal_group
from emp order by 3 asc;
*switch case느낌
select ename, deptno,
case deptno -- key값
when 10 then "Accounting" -- 10이 case 하나하나;
when 20 then "Research"
when 30 then "Sales"
when 40 then "Operation"
else "Etc."
end as dname
from emp;
*rollup 소계 처리
-- deptno 대로 정렬
select deptno, sum(sal) from emp group by deptno with rollup;
-- deptno 10이면서, job이 같은것~
select deptno, job, sum(sal) from emp group by deptno, job with rollup having deptno = 10;
-- 소계별로 정리 출력
select
case deptno
when 10 then '10'
when 20 then '20'
when 30 then '30'
when 40 then '40'
else '소계'
end as 부서번호,
sum(SAL) as 부서별연봉합계
from emp
group by deptno with rollup;
*order by : select 절을 통해 출력된 결과물을 다시 특정 칼럼을 기준으로 정렬, 사용 많이 할 수록 성능 저하됨.
select job, round(avg(sal)) from emp where sal is not null group by job
having avg(sal) > 1000 order by avg(sal) desc;
-- 두 차례 정렬, 한번 전체 정리된 걸 다시 한번 order by 하는 것이기에 성능 저하.
select * from emp order by sal desc, comm desc;
-- order by절에서 alias를 사용하는 경우 -> 칼럼의 이름이 함수 등을 이용하여 복잡한 경우에 사용함.
-- asc가 default, desc는 직접 입력
-- asc에서 null은 가장 마지막에 출력, desc에서는 가장 먼저 출력 -> null이 가장 큰 값이라고 보면됨;
*order by 예제
select * from emp;
select ename, job, hiredate from emp order by hiredate;
select empno, ename from emp order by empno desc;
-- 부서 번호 순으로 출력하되 같은 부서 내의 사원을 출력할 경우 최근 입사 사원부터 출력
select deptno, empno, hiredate, ename, sal from emp order by deptno, hiredate desc;
2)Join
-조인의 종류는 INNER, OUTER, EQUI, ANTI, SELF, SEMI, CARTASIAN, ANSI JOIN 등이 있음. 모두 다 독립적이지 않고 연관되어 있음. 기본적으로 inner join으로 다 커버 가능함.
-equi join은 deptno와 특정 테이블에서 PK이자 FK인 칼럼을 연결해서 두 개의 상이한 테이블을 조인하는 것임.
-non equi join은 특정 칼럼을 범위로 join 시킴.
*equi join
-여러 방법은 그냥 알아두고, inner join만 써도 됨(90%)
-테이블 관계를 너무 많이 맺으면 심각한 성능 저하가 옴.
-조인은 최소한으로만 해야함. 사용을 많이 할수록 그냥 테이블 병합 시키는게 나음.
-- equi join, 테이블 2개를 합쳐서 처리하는 것; where에서 deptno 기준으로 비교연산해서 합침 -> 매칭된 상태에서 select함;
-- d.deptno를 e.deptno와 where로 연결 시킴; select 칼럼 선택시 겹치는 것은 e. d.으로 설정해줘야함. 콤마로 함께 나열
-- emp e, dept d와 같이 allias 설정해야함.
-- 비표준
select ename, sal, e.deptno, dname, loc from emp e, dept d where e.deptno = d.deptno;
-- ANSI/ISO 표준 방식
-- e.deptno = d.deptno에 대하여(on), emp e가 dept d을 inner join(의존, 참조)하는 구조!
-- deptno의 경우 연결되는 것이기 때문에, deptno select시, 앞에 'e', 'd'와 같이 명시 해야함.
-- 표준 방식에 익숙해지는게 편할 듯 함!
select * from emp e inner join dept d on e.deptno = d.deptno;
-- 유일한값은 allias 붙이지 않음.
select empno, ename, e.deptno, dname, loc from emp e, dept d where e.deptno = d.deptno;
select empno, ename, emp.deptno, dname, loc from emp, dept where emp.deptno = dept.deptno;
-- inner join 형태
select * from emp inner join dept on emp.DEPTNO = dept.DEPTNO;
-- explain 붙이면 SQL문 설명 나옴;
explain select empno, ename, e.deptno, dname, loc from emp e, dept d where e.deptno = d.deptno;
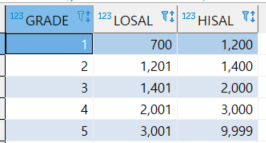
*non equi join
-마찬가지로 표준 방식으로 익숙해지는게 깔끔할 것 같음.
-쇼핑몰 등급 non equi join
-쇼핑몰 매출액을 grade에 join 걸어서 자동으로 등급 업데이트 시키면 됨.
-- 표준
select ename, sal, grade from emp e join salgrade s on sal between losal and hisal where grade > 1 order by grade desc;
-- 비표준
select ename, sal, grade from emp e, salgrade s where (sal >= losal and sal <= hisal) and grade > 1 order by grade desc;
*기타 다양한 join
-- 3개 테이블 조인 / 비표준
select e.ename, d.dname, s.grade
from emp e, dept d, salgrade s
where e.deptno = d.deptno
and (e.sal between s.losal and s.hisal);
-- 표준, 3개부터는 표준 방식이 훨씬 깔끔함(equi + non-equi)
select e.ename, d.dname, s.grade from emp e inner join dept d
on e.deptno = d.deptno (inner - 생략 가능) join salgrade s on e.sal between s.losal and s.hisal where s.grade > 3;
-- natural join은 상이한 2개의 테이블에서 '자동'으로 같은 칼럼이름 찾아주는 것임. dept가 2개 칼럼에 중복되서 나타 나는 것을 방지해줌.
select deptno, empno, ename, dname from emp natural join dept;
-- natural join 표준 방식. alias없이 본 테이블 이름으로 함!
select emp.deptno, empno, ename, dname from emp inner join dept on emp.deptno = dept.deptno;
-- using 조건절은 natural join에서 칼럼을 선택할 수 있음.
-- 겹치는 항목(deptno) select 시 d. e.이 아니라 오리지널 그대로 써야함. 안겹치는 것은 그대로해도되고, e. d. 붙여도됨;
select ename, deptno, dname, loc from dept d join emp e using (deptno);
-- 칼럼을 지정하지 않으면 조인될 칼럼이 가장 먼저 출력됨;
select * from dept d join emp e using (deptno);
-- cross join이란 조인으로 발생할 수 있는 모든 경우의 수를 만듬(cartesian product); 테스트 같은거 할 시 의미 있을 듯?!
select empno, ename, job, dname, loc from emp cross join dept;
-- left [outer] join => 좌측 테이블 기준으로 데이터를 맞춰서 조인 / '[]'안의 내용은 생략 가능하다는 뜻;
select * from emp e left outer join dept d on e.deptno = d.deptno;
-- left, right 모두 방향성만 차이가 있고 데이터는 같음;
-- 기준 테이블이 무엇이냐에 따라 다름, 쇼핑몰 고객정보 -> 상품정보;;;
select * from dept d left outer join emp e on d.DEPTNO = e.DEPTNO;
select * from emp e right outer join dept d on e.DEPTNO = d.DEPTNO;
-- full [outer] join => mysql은 지원하지 않음
select col_names,....
from table1 t1 full [outer] join table2 t2
on t1.col_name = t2.col_name;
error (mysql 지원안함)
select * from emp e full outer join dept d
on e.DEPTNO = d.DEPTNO;
-- full [outer] join(MySQL에서는 지원하지 않음); -> 대체방식이 union 연산자(병합연산자, 중복은 제거);
-- union은 row를 병합하는 개념 <-> 칼럼은 scala subquery;
-- 빈 row 값까지 나옴
-- union, unionAll 사용 시 칼럼값은 항상 일치시킬 수 있도록 주의할 것.
select * from emp e left join dept d on e.DEPTNO = d.DEPTNO
union select * from emp e right join dept d on e.DEPTNO =d.DEPTNO;
-- union all(중복 유지), row들이 2번씩 반복됨 / a,b 테이블 모두에 존재 하기 때문
select * from emp e left join dept d on e.DEPTNO = d.DEPTNO union all select * from emp e right join dept d on e.DEPTNO =d.DEPTNO;
-- self join이란 동일한 테이블을 서로 다른 테이블처럼 인식해서 사용
-- 상위 계층 확인하고자 할 때 사용~ 사원->매니저->상위관리자
select e1.empno as 사원, e1.mgr as 관리자, e2.mgr as 차상위관리자
from emp e1, emp e2 where e1.mgr = e2.empno;
select e1.empno as 사원, e1.mgr 관리자, e2.mgr 차상위관리자 from emp e1
left outer join emp e2 on e1.mgr = e2.empno;
*예제
select ename, sal, loc from emp e inner join dept d on e.deptno = d.deptno where loc = "new york";
select ename, hiredate from emp e inner join dept d on e.deptno = d.deptno where dname = "accounting";
select ename, e.DEPTNO, job from emp e inner join dept d on e.deptno = d.deptno where job = "manager";
-- 1번(team, stadium)
select region_name, team_name, t.STADIUM_ID, stadium_name, seat_count from team t inner join stadium s
on t.STADIUM_ID = s.STADIUM_ID;
-- 2번(player, team, stadium)
select PLAYER_NAME, p.position, t.REGION_NAME, t.TEAM_NAME , s.STADIUM_NAME from player p inner join team t on p.TEAM_ID =t.TEAM_ID join stadium s on t.STADIUM_ID = s.STADIUM_ID;
-- 4번(stadium, team)
select team_name, s.STADIUM_ID, STADIUM_NAME from stadium s inner join team t on s.STADIUM_ID = t.stadium_id order by s.STADIUM_ID ;
-- 5번(player, team, stadium)
select PLAYER_NAME, t.REGION_NAME , t.TEAM_NAME , s.STADIUM_NAME, p.`POSITION` from player p inner join team t on p.TEAM_ID =t.TEAM_ID join stadium s on t.STADIUM_ID = s.STADIUM_ID where p.position = "GK" order by PLAYER_NAME ;
-- 6번
-team이라는 같은 테이블을 각각 ht, awt으로 설정해서 sc 테이블의 home & away팀에 따로 연결해야 본 문제 해결 가능!
select st.stadium_name as 경기장, st.stadium_id as 경기장ID, sc.SCHE_DATE as 경기일정, ht.TEAM_NAME as 홈팀이름,
awt.TEAM_NAME as 원정팀이름, sc.HOME_SCORE as 홈팀점수, sc.AWAY_SCORE as 원정팀점수 from schedule sc join stadium st on sc.STADIUM_ID = st.STADIUM_ID join team ht on sc.HOMETEAM_ID = ht.TEAM_ID
join team awt on sc.AWAYTEAM_ID = awt.TEAM_ID where abs(home) >= abs(AWAY_SCORE) +3;
-- 7번
-- stadium 테이블에 등록된 경기장에는 hometeam_id가 없는 곳도 있다. 홈팀이 없는 경기장의 정보도 같이 출력
select stadium_name, s.STADIUM_ID, SEAT_COUNT, HOMETEAM_ID, t.TEAM_NAME from stadium s left outer join team t on s.HOMETEAM_ID = t.TEAM_ID order by HOMETEAM_ID ;
3)View, limit, index
*View
-table은 데이터 담는 역할, view는 논리적으로만 데이터가 존재하고 보여주는 역할을 함.
-동적 다이나믹 뷰,
-- View : a,b 칼럼이 너무 많아서 다 합치기는 그렇고..... -> view 사용
-- join 계속 해서 사용하는 것보다 성능적으로 좋음, +@로 보안(민감한 정보는 제외)
-- 업데이트 내용까지 실시간으로 받아옴;
-- view도 어쨌든 공간을 차지하기 때문에 안만들어도 되는 것까지 만들 필요는 없음.
create or replace view v_player_team as select p.player_name, p.back_no, p.team_id, t.team_name from player p join team t on p.TEAM_ID = t.TEAM_ID;
-- View 조회는 table 조회와 같음!
select * from v_player_team where player_name like '%강%';
-- view drop 시키기
drop view v_player_team;
-view 예제
-- 예제1번
create or replace view emp_view as select empno, ename, deptno, mgr from emp;
select * from emp_view;
-- 예제 2번
create or replace view sal_view as select deptno, max(sal), min(sal) from emp group by deptno;
select * from sal_view;
-- 예제 3번 : view 생성 시 명칭 새로 부여 했다면, 해당 명칭으로 select해야지 값 조회 가능함.
create or replace view emp_view(사원번호, 사원명, 부서번호, 상관) as select empno, ename, deptno, mgr from emp;
select 사원번호, 부서번호 from emp_view;
-- 예제 4번, limit 3으로 뽑을 자료 개수 선택 가능함
create or replace view sal_top3_view as select empno, ename, sal from (select empno, ename, sal from emp order by sal desc limit 3) e;
select * from sal_top3_view;
*limit
-10이면 10개
-0번부터시작이기에, 3,4찍으면 3번부터 4번까지 2개 나옴.
-- sqlex.emp와 같이 다른 데이터베이스 자료 끌고 올 수 있음.
-- limit 2, 3하면, 2번부터 3명
-- limit는 order by와 같이 감. limit 2 => 첫번째 0, 부터 2개라는 것
-- limit 1,3이라면 1번째 자리부터 3명
예시
select * from soccer.team order by region_name limit 5;
select * from soccer.team order by region_name limit 1,3;
*index
-- index 사용 목적 : DB에서 다른 칼럼 보다 더 빠르게 데이터를 조회해야 하는 경우, 검색 쿼리 속도를 향상 시키기 위해!
-- 단, 데이터가 자주 업데이트(수정, 삭제, 생성)되는 칼럼에는 인덱스를 만들지 않는게 좋다. 그 이유는 인덱스가 있는 테이블을 업데이트 하는 것은 인덱스가 없는 테이블을 업데이트 하는 것보다 더 많은 비용이 요구됨.
-- 결론은 자주 검색되는 칼럼에 대해 인덱스를 작성하는 것이 좋다.
-- 기본적으로 PK에 인덱스, 그외에도 추가 가능
create table home_stadium as select * from stadium where hometeam_id <> "";
-- 기존 테이블에 인덱스 부여
create index idx_team_id on home_stadium (stadium_id);
alter table home_stadium add index idx_stadium_id (stadium_id);
-- 테이블 생성 시 인덱스 부여
create table tbl_stadium (
std_id int(11),
std_name varchar(50),
std_loc varchar(100),
std_tel varchar(20),
primary key (std_id),
index idx_std_loc (std_loc)
);
-- 인덱스 조회
show index from tbl_stadium;
-- 인덱스 삭제 (인덱스 수정은 없음, 삭제후 재부여);
alter table tbl_stadium drop index idx_std_loc;
-- 인덱스 속도 테스트
create table test_index (
p_id int(11) auto_increment primary key,
p_name varchar(100),
t_id varchar(10),
pos varchar(10),
nat varchar(10),
hei varchar(10),
wei varchar(10)
);
-- 데이터 생성
insert into test_index (p_name, t_id, pos, nat, hei, wei)
select player_name, team_id, `position`, nation, height, weight from player;
insert into test_index (p_name, t_id, pos, nat, hei, wei)
select p_name, t_id, pos, nat, hei, wei from test_index;
-- PK는 빨리 뽑힘 / index
select p_id, t_id, pos from test_index where p_id = 123456;
-- index없는 t_id, DB툴에서는 200개만 먼저 불러준거라서 빨라보인거, 명령프롬프트 전체 출력은 엄청 오래 걸림; 검색 0.28sec 걸림, view땜시 체감시간길었음;
select p_id, t_id, pos from test_index where t_id = 'K08';
-- index 추가; 1.37sec 걸림.. 왜? 어느정도 검색하는 경험치가 쌓이면 optimizer가 트리구조를 생성해서 더 빨라짐.. -> 2차에 0.35sec;
create index idx_tid on test_index (t_id);
select p_id, t_id, pos from test_index where t_id = 'K08';
-- 결론적으로 검색을 자주 하는 칼럼에는 index를 거는게 좋음!!
'MySQL, Oracle' 카테고리의 다른 글
| May 18, 2021 - MySQL 총정리 - 1 (0) | 2021.05.19 |
|---|---|
| May 17, 2021 - MySQL 각종 에러 대처 2 (0) | 2021.05.17 |
| May 13, 2021 - how to rollback in MySQL / MySQL 롤백하는 방법 (0) | 2021.05.13 |
| May 12, 2021 - MySQL 각종 에러 대처 (0) | 2021.05.12 |
| May 11, 2021 - MySQL DB 내 특정 값의 개수 조회 / 전체 개수 조회 (2) | 2021.05.11 |


